

EMuLe
Verbesserung der Daten- und Modelleffizienz beim multimodalen Lernen
Projektleitung
Förderung
BMBF
Kurzbeschreibung
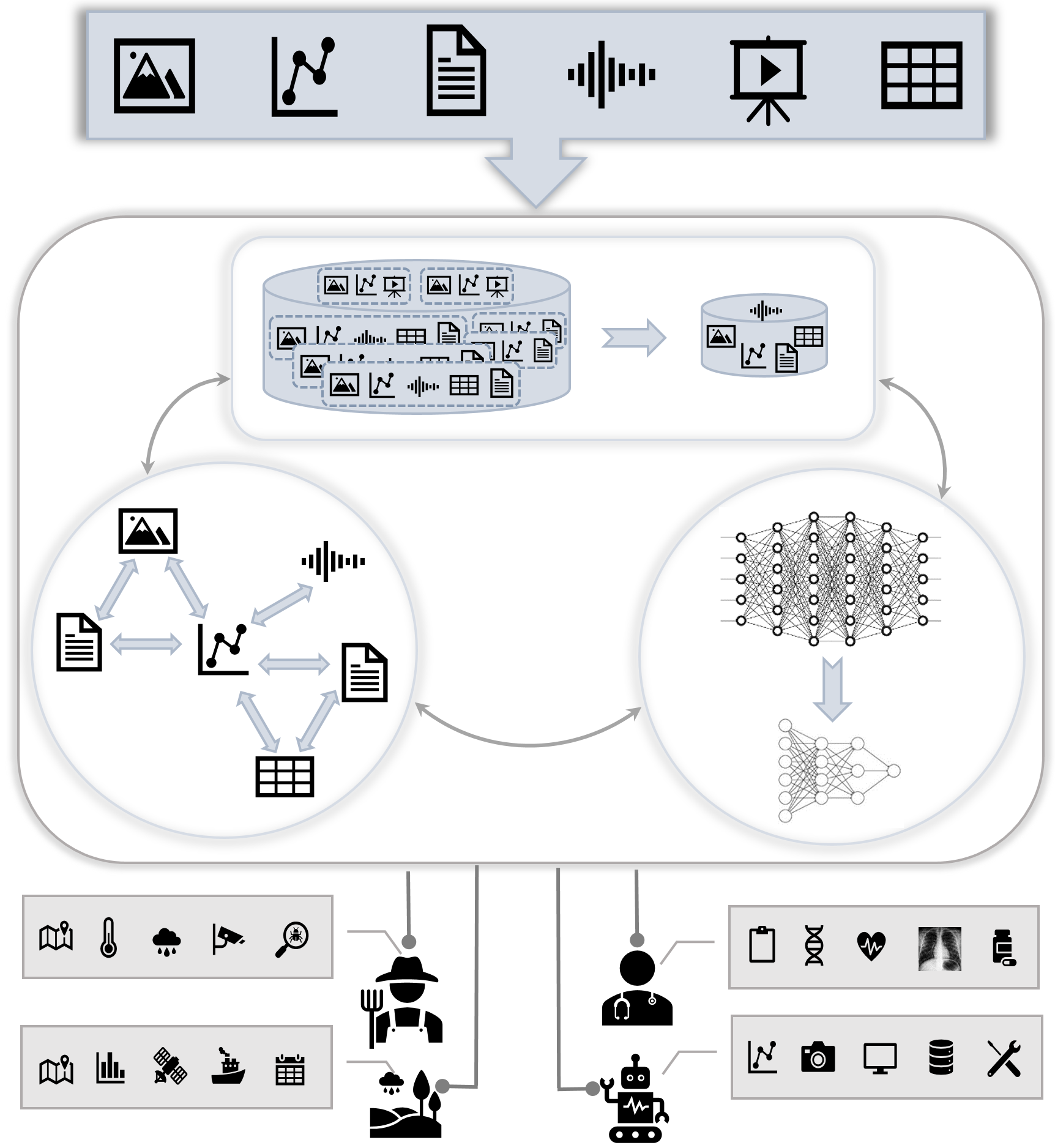
Die rasante Entwicklung großer neuronaler Netzwerke, einschließlich Transformer und großer Sprachmodelle, hat das maschinelle Lernen revolutioniert. Obwohl diese Modelle außergewöhnliche Fähigkeiten zeigen, erfordert ihr Training enorme Mengen an Daten und Rechenressourcen. Doch hinter der glänzenden Oberfläche ihrer erstaunlichen Leistungen verbirgt sich eine große Herausforderung – die Effizienz der Datenverarbeitung und die Optimierung der Ressourcen. Diese Herausforderung wird noch deutlicher, wenn diese Modelle auf multimodale Daten angewendet werden, bei denen Speicher- und Recheneffizienz entscheidend sind. Die meisten bestehenden Studien zum multimodalen Lernen konzentrieren sich hauptsächlich auf Bild- und Textmodalitäten. Zeitreihendaten mit ihren spezifischen Eigenschaften stellen jedoch eine weitere wertvolle Informationsquelle in verschiedenen Anwendungen dar, einschließlich der Sensoranalyse in der intelligenten Fertigung, im Energiemanagement, in der Präzisionslandwirtschaft und in der Präzisionsmedizin. Die Herausforderung bei der Verarbeitung solcher multimodalen Daten wird in Szenarien mit knappen Datenressourcen, eingeschränktem Zugang zu Recheninfrastruktur sowie Kosten- und Zeitfaktoren besonders deutlich. Unser Ziel ist es, daten- und modelleffiziente, robuste Deep-Learning-Frameworks für multimodale Daten in Anwendungen mit Bildern, Zeitreihen und potenziell weiteren Modalitäten vorzuschlagen. Bestehende multimodale Transformer stoßen auf zwei wesentliche Herausforderungen in Bezug auf Effizienz: (1) Datenabhängigkeit und Modellparameterkapazität: Multimodale Transformer zeigen aufgrund ihrer erheblichen Modellparameterkapazität ein datenhungriges Verhalten. Diese Abhängigkeit von umfangreichen Trainingsdatensätzen stellt ein erhebliches Hindernis dar, das ihre Anwendbarkeit und Skalierbarkeit in realen Szenarien einschränkt. Unsere Motivation ist es, die Datenqualität über die Datenmenge zu verbessern, um diese Datenabhängigkeit zu verringern und diese Modelle auch mit begrenzten Trainingsressourcen effektiv arbeiten zu lassen. (2) Zeit- und Speicherkomplexität in multimodalen Kontexten: Die inhärente Zeit- und Speicherkomplexität multimodaler Transformer, die aufgrund der Selbstaufmerksamkeit quadratisch mit der Eingabesequenzlänge wächst, stellt erhebliche Einschränkungen dar, insbesondere bei gemeinsam hochdimensionalen Repräsentationen. Wir streben an, diese miteinander verbundenen Engpässe umfassend zu adressieren und Lösungen zu finden, die die Effizienz der Trainings- und Inferenzprozesse verbessern, um multimodale Transformer letztlich zugänglicher und praktischer zu machen. Unsere zentralen Forschungsfragen drehen sich daher um die Optimierung daten-effizienter Trainingstechniken, um den für das Training dieser großen Netzwerke erforderlichen Datenbedarf zu reduzieren, und die Sicherstellung der Modelleffizienz durch eine signifikante Reduzierung der Modellgröße ohne Leistungseinbußen. Die primären Forschungsfragen lauten:
• „Wie können wir daten-effiziente Trainingstechniken optimieren, um das erforderliche Datenvolumen für das Training von Transformern und großen neuronalen Netzwerken zu minimieren, während die Modellleistung aufrechterhalten wird?“
• „Wie können wir modell-effiziente Strategien einsetzen, um die Modellgröße großer neuronaler Netzwerke signifikant zu reduzieren, während vergleichbare Ergebnisse erzielt werden?“
Laufzeit
01.09.2024 – 31.08.2027